myPeopleEnumerable.Sort(
delegate(Person p1, Person p2) {
if (p1 == null) return p2 == null ? 0 : -1;
if (p2 == null) return 1;
return string.Compare(p1.Name, p2.Name);
}
);
(which of course is functionally identical to the lambda syntax:
myPeopleEnumerable.Sort((p1, p2) => {...
)
IEnumerable / IEnumator
Allows foreach.
public interface IEnumerable { IEnumator GetEnumerator };
public interface IEnumerator {
object Current {get;}
bool MoveNext(); // We start at at index '-1', so this should be called before accessing Current for the first time
void Reset(); // Reset index to '-1'
}
AsParallel(), Cast() & TypeOf() are extension methods to IEnumerable and not part of the base interface.
LINQ
Generators
Enumerable.Range(start, count); // Generate sequential integers
Enumerable.Empty<T>; // Returns an IEnumerable<T> that is empty. Safer than returning null.
Enumerable.Repeat(itemToRepeat, count); // Returns an IEnumable<typeof(itemToRepeat)> that repeats itemToRepeate count times.
OfType(T) Filters an IEnumeravle/IQueryable to just those of type T (and their subclasses)
Group by
IEnumerable<IGrouping<string, p>p> outer = from p in people group p by p.Zip; // Its 'group x by x.field;, not SQL's 'GROUP BY x.field'
foreach(IGrouping<string, p> group in outer) {
Console.WriteLine("Zip: {0}", group.Key); // Note how Zip is duplicated into the outer enumeration as the Key property
foreach(var p in group) {
Console.WriteLine(p.Name); // This is whole p (Zip is still in here as well)
}
}
Join
var x = from order in orders
join customer in customers on order.customerNumber = customer.customerNumber
select new {order.orderNumber, customer.Name, order.orderAmount};
Distinct: Only supported in the method extension syntax (not the from-select query syntax)
ToDictionary<TKey, TItem> x = y.ToDictionary(TItem, TKey): Note the reversal of parameters
(this is due to the .NET practice of always putting source type before result type in APIs).
PLINQ
Enumerable.x replaced with ParallelEnumerable.x
.AsParallel() // Makes subsequence where/select/etc refer to ParallelEnumerable instead of Enumerable
.AsOrdered() // Preserves source order in results
.WithDegreeOfParllelism(max) // Note: upper limit, does not guarentee this degree. Current max is 64.
.WithMergeOptions // By default result accumulate in a buffer until the buffer is full or the query is
complete (AutoBuffered/Default). This can be changed to NotBuffer or FullyBuffered.
foreach is not parallel. Use .ForAll to process results of a deferred query in parallel
By default, if PLINQ thinks the query unsafe or the sequentail will be faster, it will do sequential. This
behavior can be overridden via .WithExecutionMode(...)
Misc
Instance methods on a class will be selected (silently) over extension methods with the same signature.
It's 'yield return x' you idiot, not 'return yeild x'!
HashSet<T>
ConcurrentBag<T>
new Lazy<T>(() => defaultValue, threadSafe).Value
ThreadLocal<T> x - new <T>(() => defaultValue) Works around the only-initialized-on-first-thread problem
<link> tag for a style sheet needs a 'rel=Stylesheet' attribute ('type=text/css' is not enough)
!important (boo! hiss! evil!) goes after the setting but before the terminator. e.g "border-style: none !important;"
HTML
Last Updated: 8/15/2011
Horizontal <ul> & <ol>
To get horizontal ('menu' style) lists, set <li> to inline block:
li {display:inline-block}
HTML5 span does not have width
Height and width for inline elements like <span> was depreciated in HTML4
and are ignored in (standards compliant) HTML5.
Exact meaning of display style values
none: Element is not displayed at all (and unlike
visibility: hidden
) no screen estate is consumed.
inherit: Element used the same display value as parent (by default, display
does not inherit)
block: Use all the width available (i.e. width=100%), with new line before*
and after. e.g. <div>
* if there is no content prior to this block in the element containing this block,
only one new line in total will be generated.
inline(the default): Use only the room needed (or specified).
Does not add new lines.
Inline-block: Uses only the size needed by the content (e.g. <img>)
Inline-table: ?
table & table*: Act like the equivalent *-named part of the table UI
(e.g. table-row-group)
list-item: Act like a list item (including adding the bullet marker to the
left and outside of the block)
run-in: Acts as if the next sibling block was actually in this box.
There is some debate over how this should
be interpreted, but effectively it means no trailing line feed from the
block.
Stops browsers like the IPhone browser from displaying the 'whole page / zoomed out' view,
and tells them to wrap to their actual width
By default RegEx matches are Greedy: RegEx.Match("abbcbbc","a.*c")
returns "abbcbbc". Use trailing ? for non-greedy matches. i.e. RegEx.Match("abbcbbc","a.*?c")
returns "abbc".
Named Groups
Named groups (RegEx.Match("The year is 2011", "a(?'year'\d{4})"))
are named via a leading ? and single-quoted name.
Replace
Named groups in the match can be referenced in the replace using the ${name}
syntax. See below for example (which is code from my old site that rebased images
so that Word Docs (saved as filtered HTML) could be displayed without manual editing)
Back References
Matches for a previous part of the RegEx expression can be the search can be reference
in later part for the expression using the \index syntax. For example, the
end of the following expression (</h\1>) looks fora closing header tag that
is at the same level as the opening header tag found from the front of the expression
(<h(?'level'\d))
Regex headerRegex = new Regex(@"<h(?'level'\d)(?'attr'.*?)>(?'heading'.*?)</h\1>",
RegexOptions.Compiled |
RegexOptions.IgnoreCase |
RegexOptions.Singleline);
body = imageRegex.Replace(body, "<img ${pre}src=\"Content/Notes/${source}\"${post}>");
RegexOptions
.IgnoreCase ?i
Ignores case.
match("abc", "ABC")
is false,
match("(?i)abc", "ABC")
is true.
.Singleline ?s
Increases the scope of . (matches nearly any character) to include \n as well.
Multiline ?m
Changes the behavior of ^ and $ so that they apply to each section of the string
that is separated by \n (rather than to the start and end of the entire string)
A minus sign after the inline option(s) turns them back off (e.g. ?is-)
Other
There are static helper methods on the C# base class now for match and for replace
(i.e. don't have to new up a class instance for a one-off Regex).
Replace operations can take a MatchEvaluator instance in order to programmatically
control the replacement value for each match found.
Big O
Last Updated: 2010
O(n) = upper bound version of f(n)
Ω(n) = lower bound version of f(n)
θ(n) = tight bound version of f(n)
[tight bound = when lower and upper bounds are of the same magnitude, so not every
function can be described this way]
"Everything is small compared with the dominant term", so O(n^^3) + O(n^^2)
+ O(1000n) = O(n^^3)
Multiplication is just repeated addition, so 3x O(n^^3) = O(n^^3)^^3) = O(n^^3)
n! >> 2^n >> n^3 >> n^2 >> n log n >> n >> log
n >> 1
Can only be set via Javascript (not HTML) and is visual only (checkbox still only
has two states when read)
Capture input as you type
Bind to the key up event (binding to onkeypress generates a graphical glitch on
IE where the page briefly redraws (and lays out) without the linked control present
when typing the first few characters).
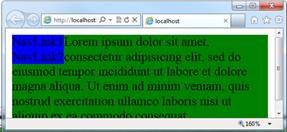
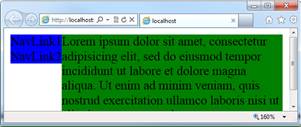
Gets me every time. By default, a normal div following a float left div wraps around
the floating div (see first figure below). Setting the overflow attribute on the
normal div to anything but the default of visible (e.g. to auto) prevents this wrapping
and gives the desired column effect (see second figure below).
NavLink1
NavLink2
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor
...
Figure 1 - With over flow:visible (default)
Figure 2 - With overflow:auto
Trees
Last Updated: 2010
Types
Random
Add a node where we'd have expected to find the leaf if it was already there.
No rebalancing takes place. OK if inserts are statistically random (i.e. uniformally distributed).
Sucks when adding volume data in key order.
Example: Root is letter M. Adding C and Z gives:
Root is letter M.
Adding C and Z gives:
M
/ \
C Z
Adding D & E gives:
M
/ \
C Z
\
D
\
E
When we wanted:
M
/ \
D Z
/ \
C E
Balanced Tree
Uses rotation operations to move distant nodes closer to the root (in the diagram above, turns the middle cell into the right hand cell).
A balanced Binary Search Tree can be used to implement a priority queue as chosing all left branches or all right branchines will return the smallest or biggest value.
Seems the formal definition of a Binary Search Tree includes a leaf value on
the node itself (i.e. there is only one type of item in the tree. If the key
check is an exact match, we return the value from that item, otherwise we go
left or right down the tree. The obvious advantage of this is that we can reduce
the number of checks / nodes in the tree. Down-side is that it can lead to
unbalanced trees (since the less than / greater than test is no based on the
value of the item, not the midpoint of the range covered by the node).]
Balanced Tree: O(log n), max height = log2(n), where n = number of
elements Unbalanced Tree (node/leaf merged): O(h) where h is the (unpredicatable) height of the tree
A balanced tree can be used to sort in O(n log n) time by inserting all values
into the tree then walking it.
Splay
Rotations + moves used keys to root when accessed.
B-tree
For data sets too large to fit in real memory. Collapses several levels
of binary search tree into one. Have to brute force the final selection of
records from those returned, but cheaper than (for example) reading multiple
nodes from disk.
Heap
A heap is tree structure where node space is reserved (such that there is always
a child left and right irrespective of if they are populated). This allows the
tree structure to be modeled as an sequential array and no pointer are required
to navigate through the stucture (provided you know what level of the tree you
are at). The root node is element 1 of the array, root.left is element 2,
root.right is element 3, root.left.left is element 4 and so on. The nth level of
the tree (the root being level 0) requires 2n slots. So element X on level
3 knows its parent must be element (X/2), it's left element must be X*2, and
it's right element must be X*2+1 [Note we used a 1-based array in order to make
this math work]
Breath-First Search (BFS)
Walk the tree tier by tier starting at the root
Depth-First Search (DFS)
Walk the nodes down recursively
Transversals
Preorder - Self, Left, Right
Inorder - Left, Self, Right
Postorder - Left, Right, Self
Perf
In a binary search tree the answer for an n-elemenet universe will be found in
log2n (possibly log2n is the n is odd) steps. Real world
is typically not so predicatable (with B-trees replacing binary search trees and
pointing to a page of ordered data rather than two individual records)
Walking a balanced tree returns all items in key order. Taking all lefts returns
returns min value, all rigths return max value (presuming less than = left
and greater than = right)